자연어 처리 및 이해에 대한 연구는 그동안 전 세계적으로 지속적인 관심을 받아온 주제입니다. 하지만 연구의 기반이 되는 공개 데이터셋을 이용하는 데는 한계가 있었습니다. 대부분 영어로 이루어져 한국어 고유의 특성을 고려한 연구가 어려웠기 때문입니다. 이에 스타트업 업스테이지가 KAIST, NYU, 네이버, 구글 등 국내 10개 기관과 함께 한국어 기반 AI모델의 공정한 평가를 위한 ‘한국어 자연어 이해 평가 데이터셋(Korean Language Understanding Evaluation Benchmark, KLUE)’을 구축하였으며, 셀렉트스타 또한 KLUE의 구축에 참여했습니다.
클루(KLUE)는 한국어 언어모델의 공정한 평가를 위한 목적으로 8개 종류(뉴스 헤드라인 분류, 문장 유사도 비교, 자연어 추론, 개체명 인식, 관계 추출, 형태소 및 의존 구문 분석, 기계 독해 이해, 대화 상태 추적)의 한국어 자연어 이해 문제가 포함된 데이터 집합체입니다. 영한 번역문이 아닌 일상생활에서 실사용되는 한국어 원문으로만 제작돼 한국어의 정확한 이해와 추론 능력을 평가할 수 있으며, 특히 다양한 한국어 언어모델이 동일한 평가선상에서 정확하게 비교될 수 있는 평가기준과 토대가 된다는 점에서 앞으로 한국어 자연어처리 분야의 발전을 앞당길 것으로 기대됩니다.
또한 KLUE는 누구나 데이터에 접근, 활용할 수 있는 라이선스를 부착한 국내 최초 오픈 데이터셋이라는 점에 의의가 있습니다.
About
한국어 언어모델의
공정한 평가
셀렉트스타는 더욱 스마트한 인공지능을 위한 고품질 학습 데이터를 제공합니다. 본 데이터셋은 셀렉트스타가 주최한 인공지능 데이터셋 지원사업의 일환으로, 업스테이지과 협업하여 무료로 구축하였습니다.
업스테이지(Upstage)는 2020년 10월, 김성훈 대표가 기업 AI 트랜스포메이션을 가속화 하기 위해 설립한 스타트업입니다. AI 기술을 통해 혁신이 가능한 기업의 문제들을 파악하여 이에 필요한 기본 AI 모델 및 시스템 구축을 포함한 컨설팅을 제공하고 있습니다.
업스테이지를 설립한 김성훈 대표는 세계소프트웨어엔지니어링학회(ICSME), 소프트웨어엔지니어링재단(FSE)등 세계 최고 수준의 AI 연구 커뮤니티에서 우수 논문상을 4회 수상한 바 있는 인공지능(AI)분야의 세계적인 석학으로, 전 네이버 클로바 AI 헤드이자 홍콩과학기술대학(Hong Kong University Of Science and Technology) 컴퓨터 공학부 교수입니다.
업스테이지는 고객 기업의 내부 AI 인재 양성을 지원하여 자체적인 AI 경쟁력 향상을 통한 기업의 성공적인 AI 트랜스포메이션을 도울 계획입니다. 뿐만 아니라, AI 비즈니스 경험을 녹여낸 실습 위주의 교육과 탄탄한 AI 기초 교육을 통해 AI 비즈니스에 즉각 투입될 수 있는 차별화 된 전문 인재를 육성해 기업의 AI 팀 설립에도 적극적으로 나설 예정입니다.
프로젝트 진행 소감
“셀렉트스타와 KLUE 데이터셋을 구축하며 가장 인상적이었던 부분은 ‘데이터 품질 관리’였습니다. 상당히 어려운 난이도와 촉박한 일정이었음에도 불구하고 일관된 데이터 작업이 가능하도록 가이드라인이 수립되었고, 고품질 데이터를 만들 수 있는 작업자 선발과 교육, 전수 검사가 이뤄졌습니다. 셀렉트스타 담당자 분들의 역량과 열정 덕분에 대표 한국어 NLP 벤치마크 데이터셋인 KLUE가 무사히 세상에 나올 수 있었다고 생각합니다.”
업스테이지/ KLUE 프로젝트 총괄 박성준 연구원
데이터셋 스펙
TC
210,000 분류 태그 (70,000 개의 헤드라인 * 3 종의 분류)
STS
105,000 유사도 점수 레이블 (15,000 쌍의 문장 * 7 개의 점수)
NLI
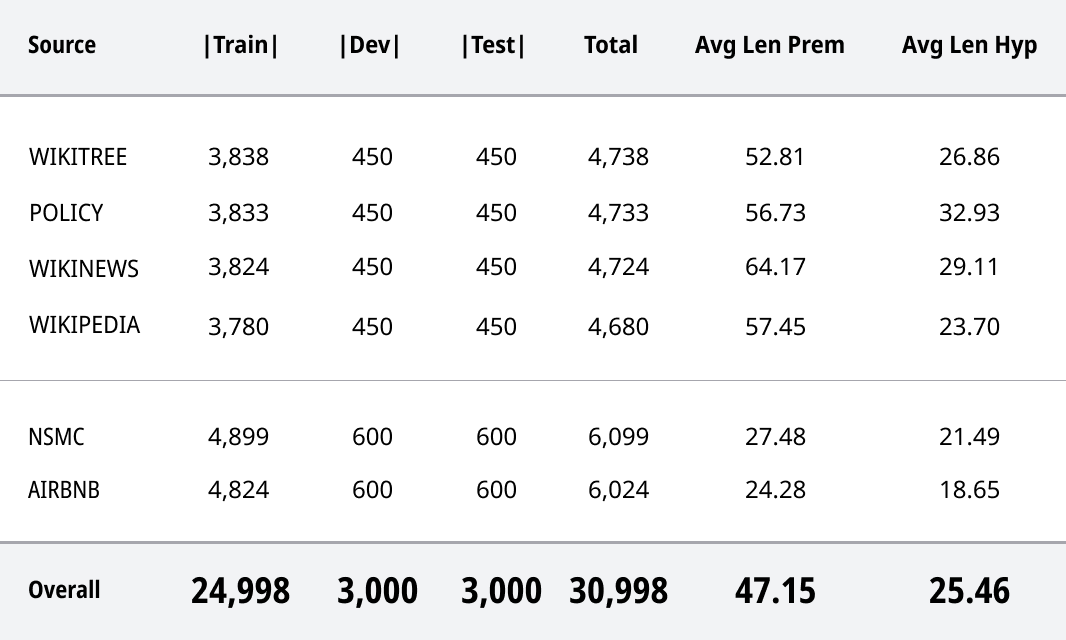
30,998 문장 세트
KLU-NLI의 통계. 첫 세 열은 각각 train, dev, test 세트에 포함된 문장 쌍의 수이다. Avg Len Prem과 Avg Len Hyp은 각각 전제와 가설 문장의 평균 글자 수를 의미한다.
출처_KLUE 논문
MRC
29,313 질문 문장 (Type1: 12,207/ Type2: 7,895/ Type3: 9,211)
데이터 수집 및 가공 방법
KLUE 데이터셋에 해당하는 8개 종류의 한국어 자연어 이해 문제 중, 셀렉트스타는 절반에 해당하는 뉴스 헤드라인 분류(Topic Classification, TC), 문장 유사도 비교(Semantic Textual Similarity, STS), 자연어 추론(Natural Language Inference, NLI), 그리고 기계 독해 이해(Machine Reading Comprehension, MRC) 데이터셋을 구축했습니다.
뿐만 아니라, 셀렉트스타 주관의 ‘인공지능 데이터셋 지원사업(dataset.or.kr)’을 통해 KLUE 데이터셋 스폰서로도 참여하였습니다.TC와 STS의 경우, 특정 조건을 통해 자격이 주어진 인원들을 통해 보다 정확한 품질의 데이터셋을 구축할 수 있었습니다.
Data Collection
뉴스 헤드라인 분류
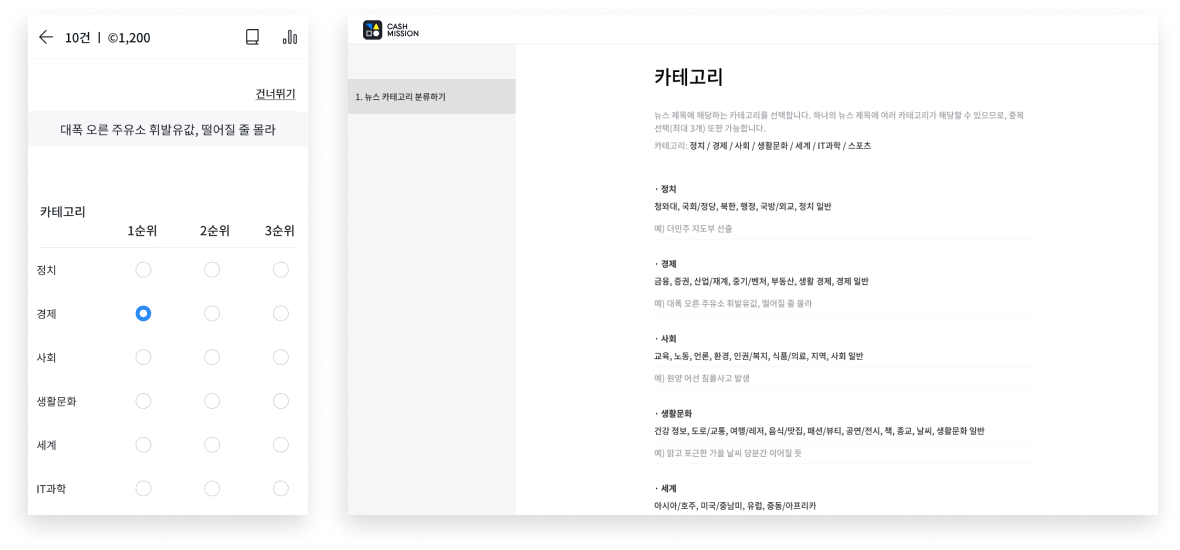
헤드라인 분류를 통해 주어진 글의 주제를 분류하는 학습 데이터를 제공하고자 합니다.
1) 온라인에서 뉴스 헤드라인 수집 2) 주어진 헤드라인에 대하여 3명의 작업자가 각각 주제를 레이블링- 7개의 카테고리 중 관련성에 따라 최대 3개의 주제를 선택 → 개인 정보, 사회적 편견, 혐오 발언 등이 포함된 헤드라인은 작업자에게 신고를 요청하여 추후에 직접 확인 후 데이터셋에서 제거
셀렉트스타의 크라우드소싱 플랫폼 '캐시미션(앱)'에서 크라우드 유저들이 뉴스 카테고리 분류하기 미션을 직접 참여하여 일부 데이터의 수집 및 가공을 진행했습니다.
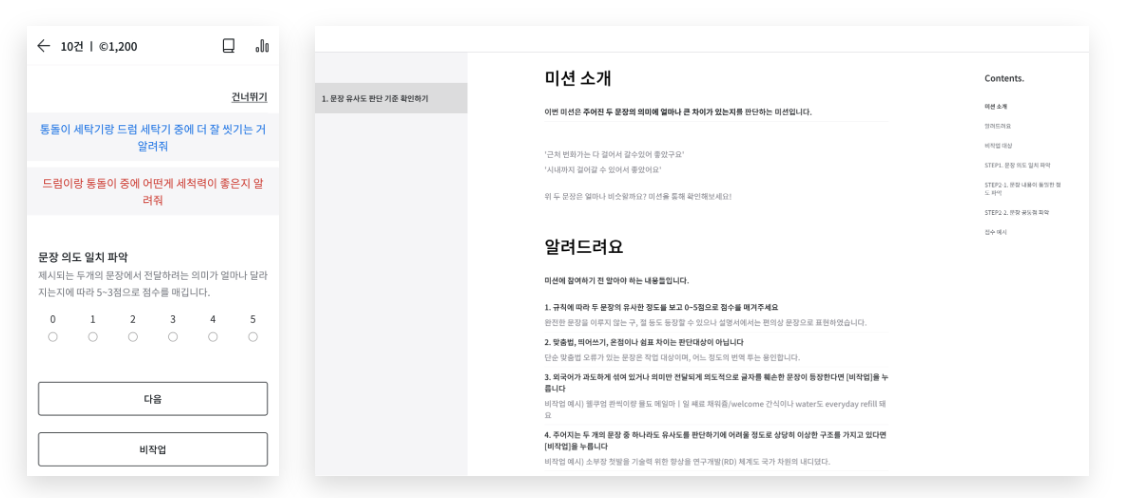
MRC(기계 판독 이해)는 주어진 텍스트 구절을 읽을 수 있는 모델의 능력을 평가하기 위해 고안된 작업입니다. 수능 언어 영역 이상의 고난이도 작업으로 글귀에 대한 질문, 즉 글귀의 이해력에 대한 질문에 답합니다.
1) 제공된 본문에서 3가지 type의 질문-답변 세트 생성 (text annotation) 2) 각 질문-답변 세트에 세 명의 검수자를 배정
타입별 소개
Question Paraphrasing (Type 1) : Type 1은 문장과 질문의 겹치는 단어 사용을 피하기 위해 paraphrasing을 유도합니다. 이를 통해 모델이 동의어가 사용된 문장에 올바른 답을 유추해 낼 수 있는지 확인할 수 있습니다.
Multiple-Sentence Reasoning (Type 2) : Type 2는 다양한 문장을 근거로 하는 질문을 만듭니다. 즉, 두 문장 이상을 통해 답을 구할 수 있어야 합니다.
Unanswerable Questions (Type 3) : Type 3는 주어진 문장만으로는 답을 추론할 수 없는 경우입니다.
Sample Data
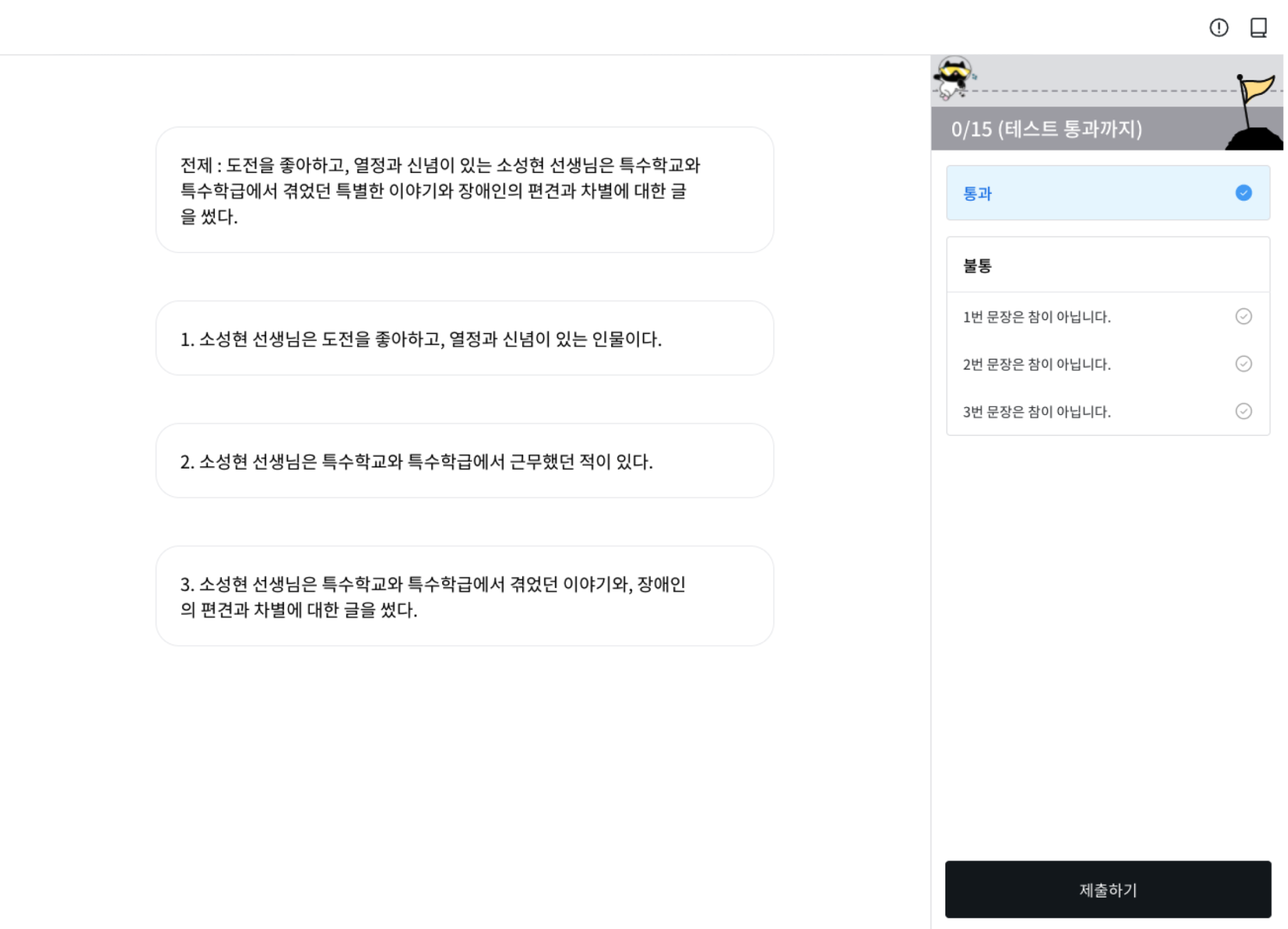
QA 문항 생성은 ‘지문’을 보고 ‘질문' 및 ‘답변’을 생성하는 과정으로 구성됩니다.
한겨울에 봄꽃 ... 지구촌 곳곳 이상고온_한경_국제
유럽과 미국을 비록해 세계 각국에 이상고온 현상이 나타나고 있다. 겨울철 함박눈이 내려야 할 곳에 봄꽃까지 피고 있다. 따뜻한 날씨에 나들이객이 늘면서 음식점과 골프장 등은 반색하고 있지만 겨울철 옷이 팔리지 않아 의류업체들은 울상이다. 글로벌 에너지 회사들은 가뜩이나 저유가로 힘겨운 상황에서 난방 수요 감소라는 '악재'까지 만났다. 러시아 기상철에 따르면 혹독한 추위로 악명 높은 모스크바의 낮기온이 22일(현지시간) 7도까지 치솟았다.1936년 이후 79년 만에 최고 기온으로 예년(평균 영하 6.5도)보다 10도 이상 높다. 기상 전문가들은 이상고온 원인을 엘니뇨 현상으로 설명하고 있다. 엘니뇨는 적도 부근 해수면 온도가 상승하는 현상으로 폭우나 가뭄, 겨울철 이상고온 등의 원인이 된다. 이상고온에 에너지 회사들은 전전긍긍하고 있다. 미국 대형 투자은행인 골드만삭스는 22일 발효한 보고서에서 “올겨울 이상고온으로 난방용 천연가스와 등유 소비가 감소하고 있다”며 “원유 공급 과잉과 세계 경제성장 둔화 등에 따라 약세가 이어지는 에너지 가격을 더욱 끌어내릴 것”이라고 전망했다. 유가가 더 떨어질 수 있다는 전망이 제기되면서 미국 3위 에너지업체 코노코필립스는 러시아 원유개발사업에서 완전히 철수하겠다고 발표했다. 유럽 최대 에너지업체 로열더치셸은 지난 4월 인수를 발표한 영국 천연가스업체 BG그룹에 대해 50억달러 상당의 투자를 축소할 계획이다.
sentence
러시아 기상철에 따르면 혹독한 추위로 악명 높은 모스크바의 낮기온이 22일(현지시간) 7도까지 치솟았다.
미국 대형 투자은행인 골드만삭스는 22일 발효한 보고서에서 “올겨울 이상고온으로 난방용 천연가스와 등유 소비가 감소하고 있다”며 “원유 공급 과잉과 세계 경제성장 둔화 등에 따라 약세가 이어지는 에너지 가격을 더욱 끌어내릴 것”이라고 전망했다.