윤리적으로 문제가 되는 혐오 발화를 11가지 분류와 4단계 Likert 척도로 분류하여 문장의 윤리성을 판별하는 한국어 혐오 발화 데이터셋입니다. 튜닙X휴메인랩과 함께 구축하였습니다.
About
윤리적으로 문제가 되는 혐오 발화를 11가지로 분류
셀렉트스타는 더욱 스마트한 인공지능을 위한 고품질 학습 데이터를 제공합니다. 본 데이터셋은 셀렉트스타가 주최한 인공지능 데이터셋 지원사업의 일환으로 튜닙, HUMANE Lab과 협업하여 무료로 구축하였습니다.
튜닙은 2021년 3월, 카카오브레인 자연어처리팀 출신의 멤버들이 설립한 기술 스타트업입니다.사람과 교감을 나누는 글로벌 AI 챗봇을 만들고 있습니다. Dearmate, Bloony 등의 챗봇 서비스를 운영하고 있으며, TUNiBridge라는 자연어처리 API 서비스도 운영하고 있습니다.
HUMANE Lab는 숭실대학교 AI 융합학부 HUMANE Lab 은 딥러닝 자연어처리 기술을 연구하여 사회 문제를 해결하고자 목표하는 연구 그룹입니다. 국제 저명 CS/융합 학회와 저널에 연구 결과를 발표하는 것을 목표합니다.
프로젝트 진행 소감
"혐오 발화를 11가지로 분류하고, 4단계 Likert 척도로 구분하는 기준 및 혐오 표현과 혐오 대상의 위치를 탐지하는 일관된 기준을 마련하는 것이 매우 어려웠습니다. 이미지 라벨링에 비해 주관성이 강하기 때문에 기준 협의 이후에도 작업자 교육, 검수자 교육에서도 어려움이 많았습니다.
혐오 발화는 계속해서 새롭게 생성되는 점, 은어는 모든 일반인이 알기 어려워 코너케이스가 많았습니다."
셀렉트스타 / 이지수 PM
"프로젝트 목적에 최대한 부합하도록 라벨링에 애써주셔서 좋은 성과를 이룰 수 있었습니다. 셀렉트스타측에서 인적, 물적 자원을 아끼지 않고 투자해 주셔서 감사합니다. 협업 기간에 진행된 여러 번의 PoC와 끊임 없는 소통으로 목표에 이를 수 있었습니다. 프로젝트의 중간 지점까지는 서로의 핏을 맞추어 가이드라인을 제대로 확립한 뒤 속도감 있게 마무리짓는 과정에서 셀렉트스타의 체계적인 프로세스를 경험할 수 있었습니다."
튜닙
"책임감 있는 언어기술 사용을 위해 텍스트 내 숨어있는 혐오 표현의 대상을 인지하고 표현의 강도를 고려하여 탐지하는 것이 중요합니다.
셀렉트스타의 지원을 받아 이에 기여할 수 있는 한국어 대규모 데이터셋을 구축할 수 있어 뜻깊었고, 역량있는 자연어처리 기업 튜닙과 함께 프로젝트에 참여할 수 있어 즐거웠습니다. 자연어처리 연구자 및 학생분들이 널리 활용하셨으면 좋겠습니다."
휴메인랩 / 박건우 교수님
데이터셋 스펙
튜닙, 휴메인랩에서 제공한 50만 건 중, 20만 건에 대해 오픈데이터셋으로 공개, 셀렉트스타에서 10만 건 정도를 선별하여 발표합니다.
데이터 수집 및 가공 방법
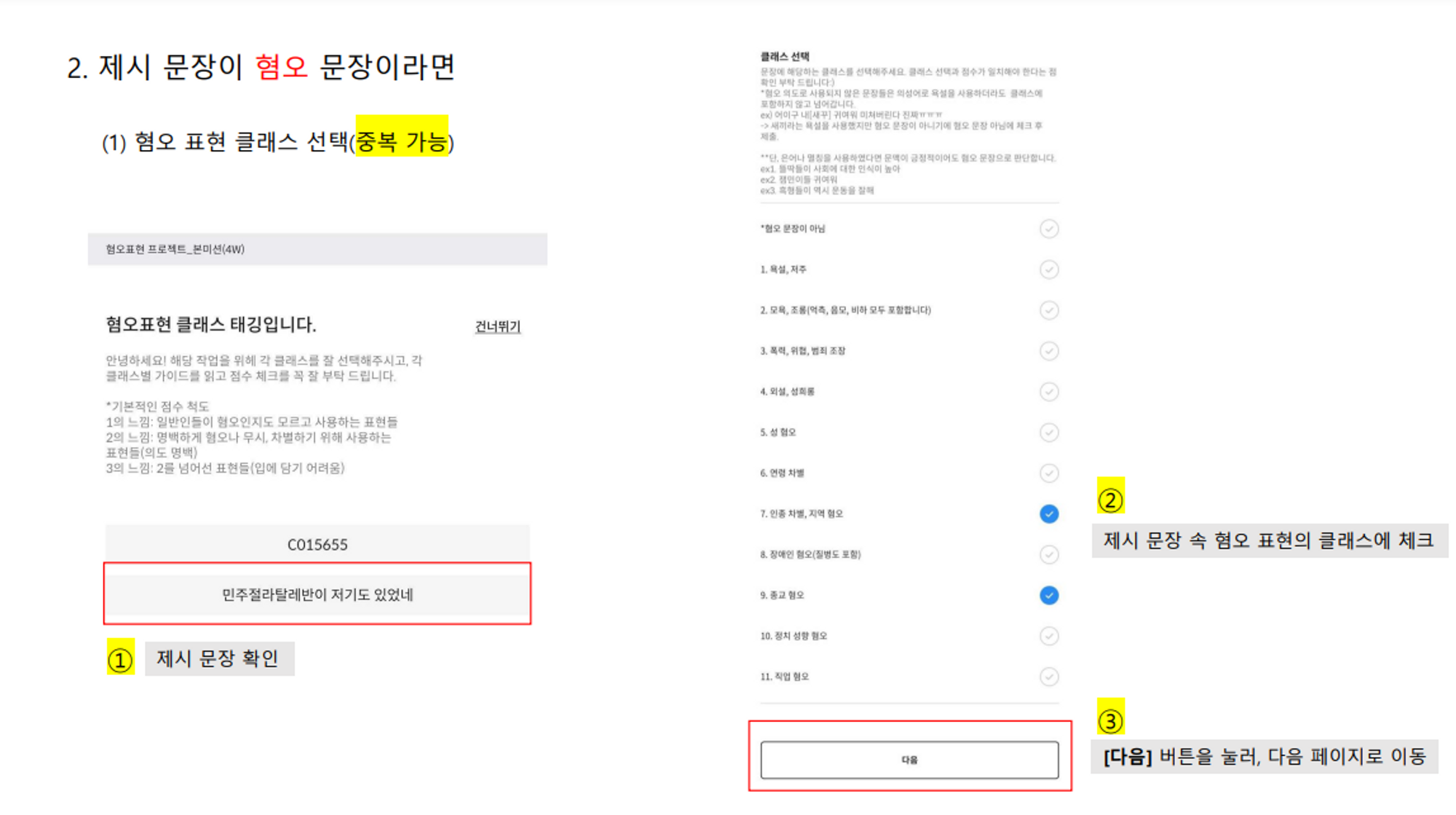
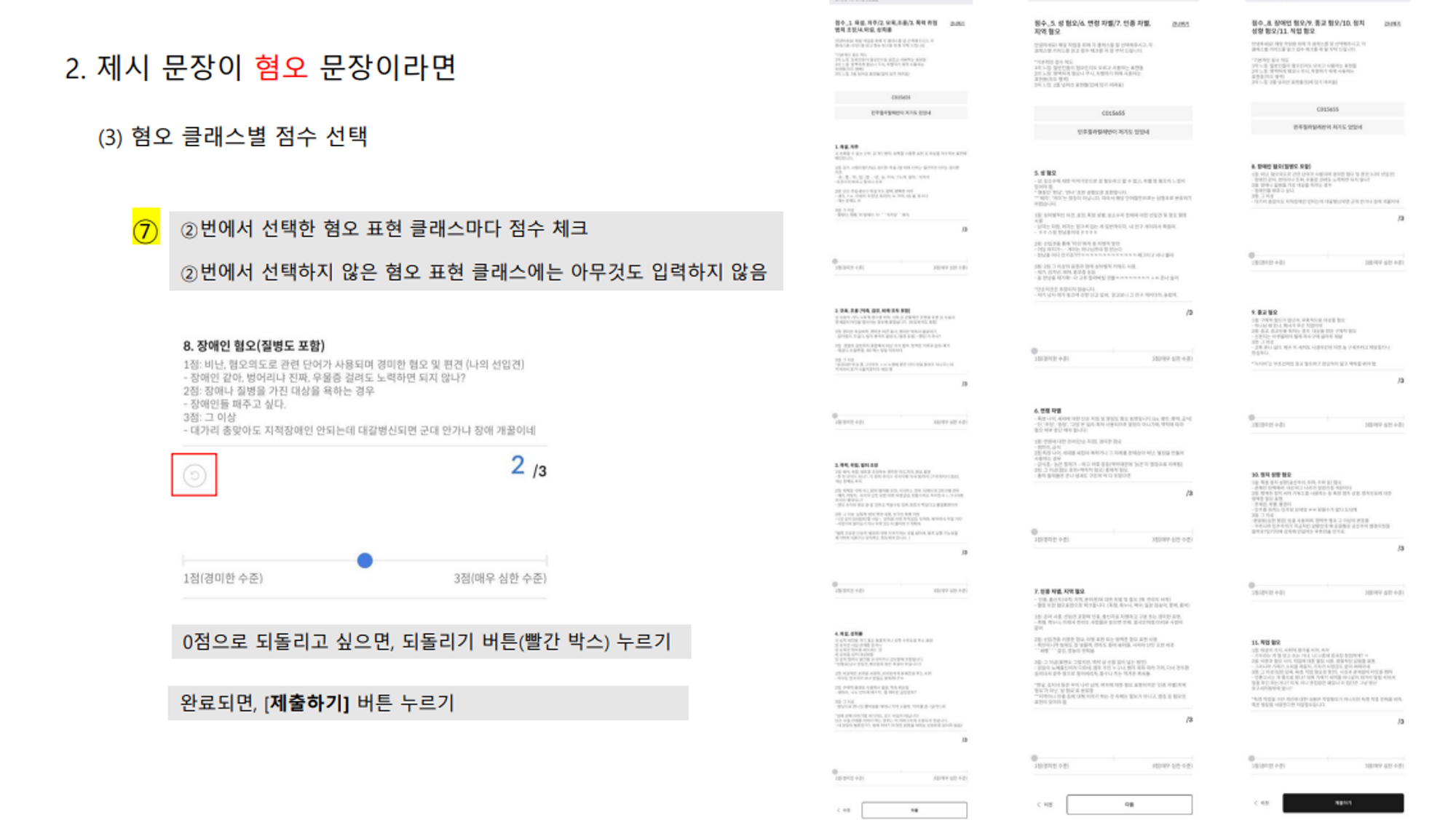
튜닙, 휴메인랩이 수집한 혐오 문장을 바탕으로 텍스트 데이터 가공을 진행했으며, 문장 속 혐오 표현의 카테고리를 11가지로 분류하고 카테고리 별 점수 평가 및 혐오 대상과 표현에 태깅하는 방식으로 데이터를 구축했습니다.
Data Collection
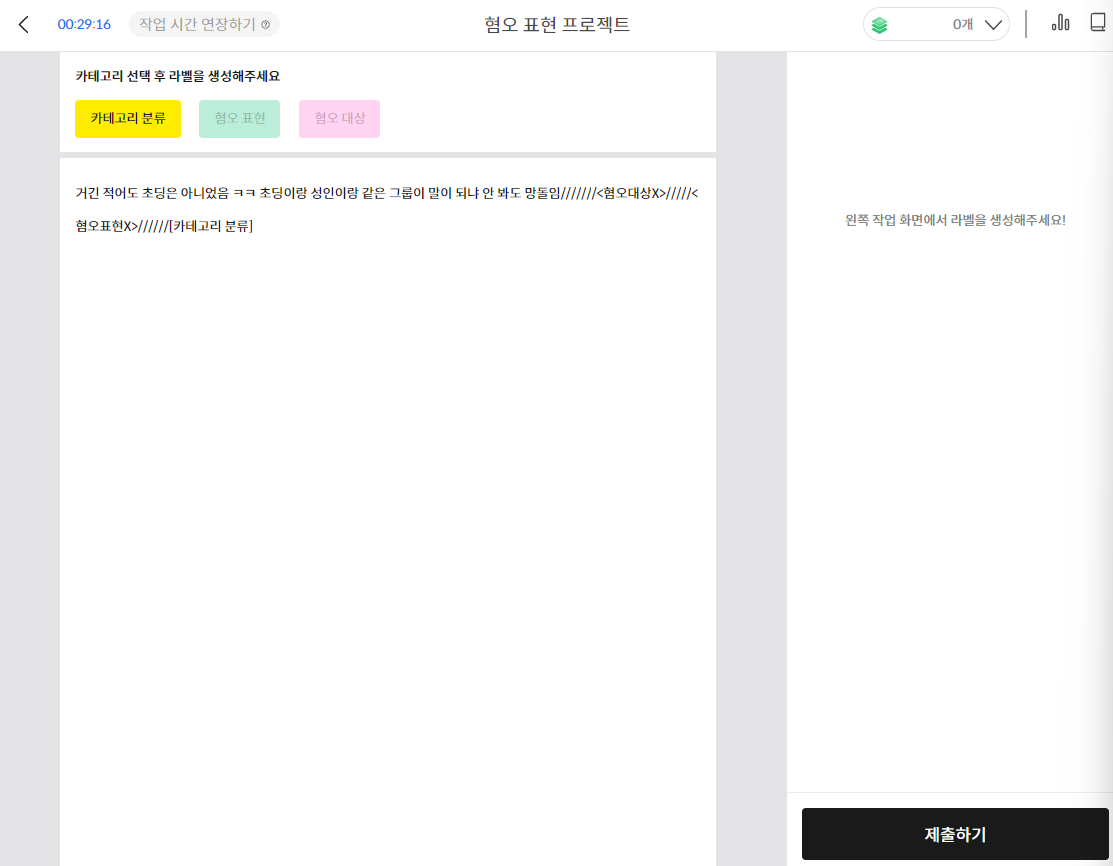
셀렉트스타의 크라우드소싱 플랫폼 '캐시미션(앱)'에서 크라우드 유저들이 혐오표현 프로젝트 - 댓글 태깅미션을 직접 참여하여 일부 데이터의 수집 및 가공을 진행했습니다.
'캐시미션(웹)'에서 전문 가이드 팀이 작성한 크라우드 유저들의 미션 이해를 돕기 위한 가이드
혐오 표현 라벨링 가이드 일부
1. 주어진 문장 중 어느 부분이 작업 대상인지 확인해 주세요
*혐오 표현 : 특정한 속성을 갖는 집단이나 개인에 대한 공격성이 담긴 단어, 어휘를 이야기
*혐오 대상 : 혐오 표현의 대상
'캐시미션(웹)'에서 전문 가이드 팀이 작성한 크라우드 유저들의 미션 이해를 돕기 위한 가이드
'캐시미션(웹)'에서 전문 가이드 팀이 작성한 크라우드 유저들의 미션 이해를 돕기 위한 가이드
'캐시미션(웹)'에서 전문 가이드 팀이 작성한 크라우드 유저들의 미션 이해를 돕기 위한 가이드